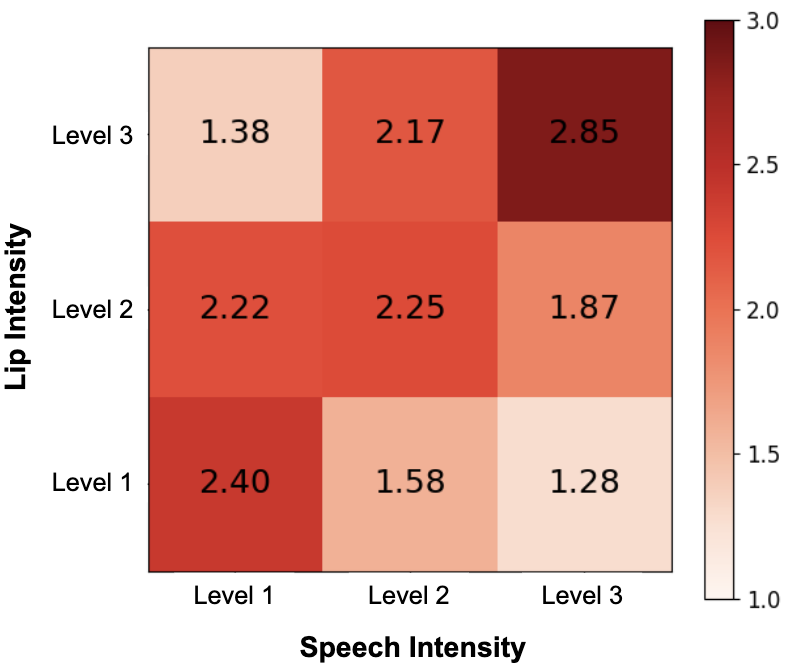
Preference scores (1-3) for 3D talking heads with varying lip movement intensities paired with different speech intensities. Humans prefer the lip movements with the intensity that match the intensity of speech.
Recent advancements in speech-driven 3D talking head generation have made significant progress in lip synchronization. However, existing models still struggle to capture the perceptual alignment between varying speech characteristics and corresponding lip movements. In this work, we claim that three criteria—Temporal Synchronization, Lip Readability, and Expressiveness—are crucial for achieving perceptually accurate lip movements. Motivated by our hypothesis that a desirable representation space exists to meet these three criteria, we introduce a speech-mesh synchronized representation that captures intricate correspondences between speech signals and 3D face meshes. We found that our learned representation exhibits desirable characteristics, and we plug it into existing models as a perceptual loss to better align lip movements to the given speech. In addition, we utilize this representation as a perceptual metric and introduce two other physically grounded lip synchronization metrics to assess how well the generated 3D talking heads align with these three criteria. Experiments show that training 3D talking head generation models with our perceptual loss significantly improve all three aspects of perceptually accurate lip synchronization.
We present intriguing findings on human audio-visual perception through human studies.
Preference scores (1-3) for 3D talking heads with varying lip movement intensities paired with different speech intensities. Humans prefer the lip movements with the intensity that match the intensity of speech.

Human preference between (A) samples with precise timing but low expressiveness, and (B) samples with high expressiveness but 100ms asynchrony—twice the commonly accepted 50ms threshold. Humans are more sensitive to expressiveness than temporal synchronization when perceiving, highlighting the importance of expressiveness.
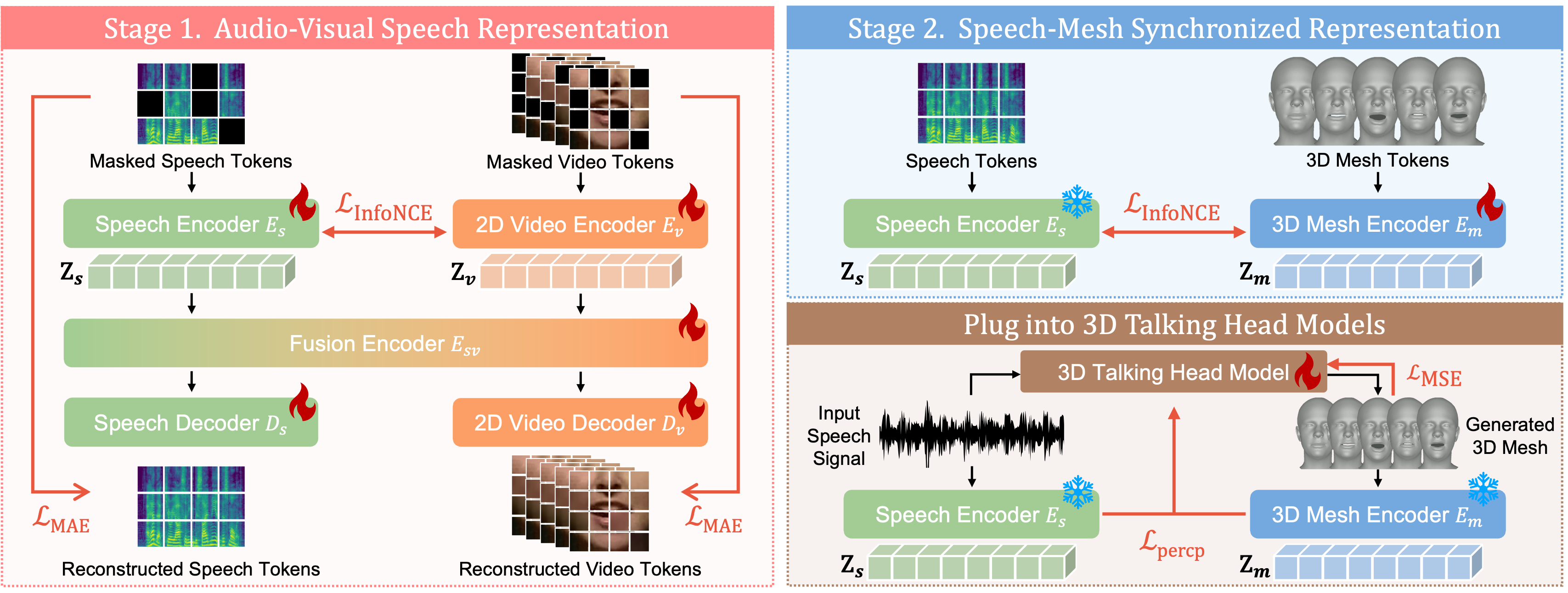
We found that our learned representation exhibits desirable characteristics we pursue for the three criteria.
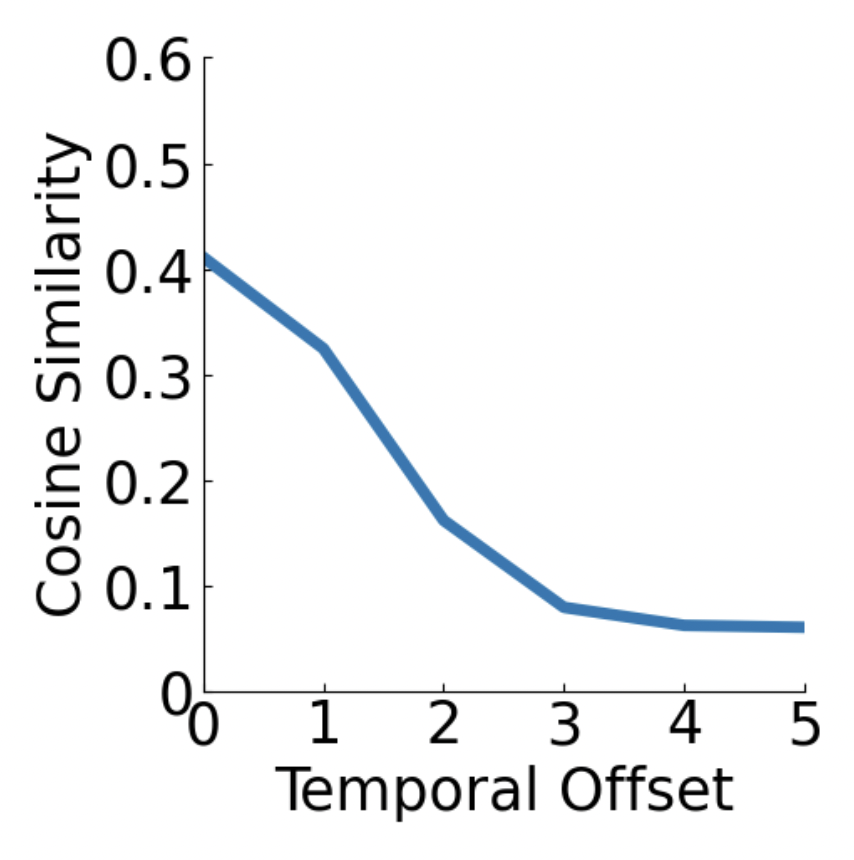
Temporal Synchronization. Cosine similarity drops when temporal misalignment is introduced between input speech and 3D face mesh.
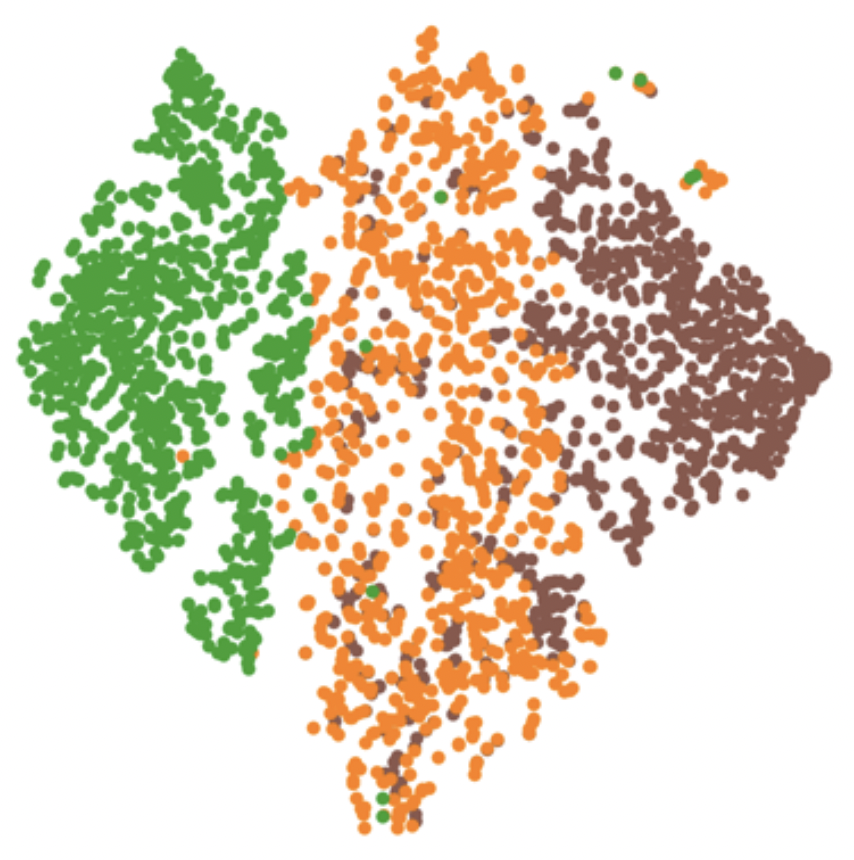
Lip Readability. Our representation tends to form distinct clusters according to phonemes, with vowels and consonants grouped closely. We also observe a directional progression in the feature space, shifting from phonemes with mouth opening (e.g., /aj/) to those with mouth closing (e.g., /f/).
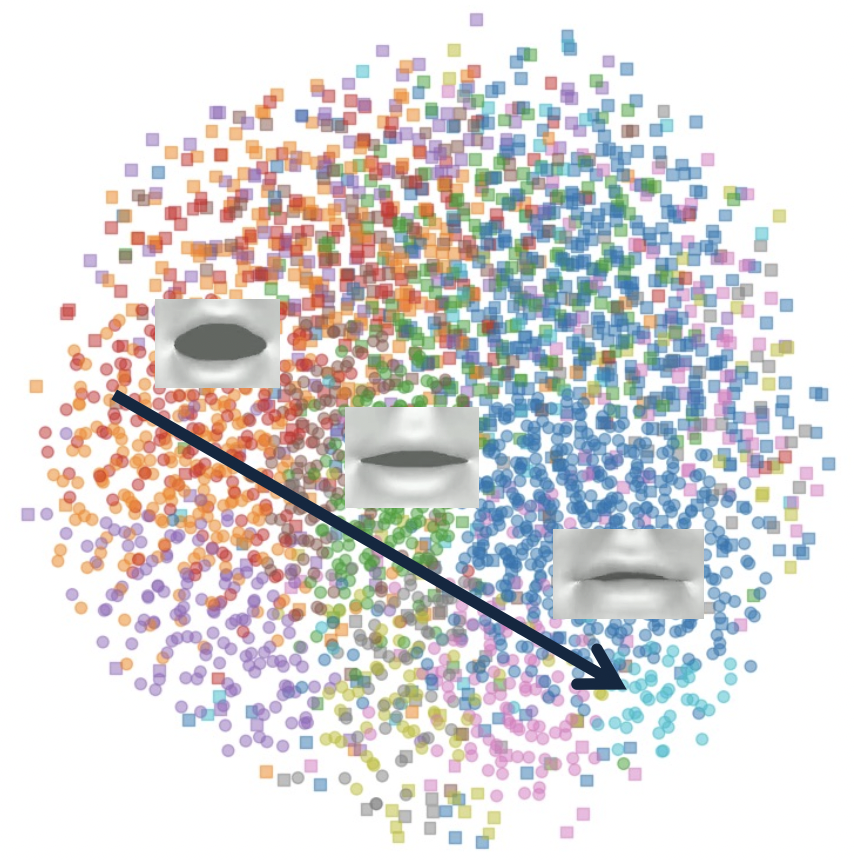
Expressiveness. We plot speech features at varying speech intensities, showing a directional trend as intensity increases from lowest to highest.
@inproceedings{chae2025perceptually,
title={Perceptually Accurate 3D Talking Head Generation: New Definitions, Speech-Mesh Representation, and Evaluation Metrics},
author={Chae-Yeon, Lee and Hyun-Bin, Oh and EunGi, Han and Sung-Bin, Kim and Nam, Suekyeong and Oh, Tae-Hyun},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={21065--21074},
year={2025}
}
We thank the members of AMILab for their helpful discussions and proofreading. This research was supported by a grant from KRAFTON AI, and was also partially supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No.RS-2021-II212068, Artificial Intelligence Innovation Hub; No.RS-2023-00225630, Development of Artificial Intelligence for Text-based 3D Movie Generation; No. RS-2024-00457882, National AI Research Lab Project) and Culture, Sports and Tourism R&D Program through the Korea Creative Content Agency grant funded by the Ministry of Culture, Sports and Tourism in 2024 (Project Name: Development of barrier-free experiential XR contents technology to improve accessibility to online activities for the physically disabled, Project Number: RS-2024-00396700, Contribution Rate: 25%).